Hey, fellow devs 👋
If you’re looking into web-scraping with javascript, then I’ve got a great, simple project to start you off, because in this tutorial, I will be showing you guys how to scrape the latest Tesla stock prices using Node.js and puppeteer.
Let’s get started!
First of all, you will need to install puppeteer using “npm i puppeteer”. Now if you don’t have npm, package.json and node_modules setup, here’s a great tutorial on how to do so: https://www.sitepoint.com/npm-guide/.
After you’ve installed puppeteer, create a new javascript file and require puppeteer on the first line:
const puppeteer = require('puppeteer');Then create the async function in which we are going to write our main code:
const puppeteer = require('puppeteer');async function start() {}
start();
Now we’re ready to start scraping.
First of all, you need to initiate a new browser instance, as well as define the url which your web-scraper is going to be visiting:
const puppeteer = require('puppeteer');async function start() {
const url = 'https://finance.yahoo.com/quote/TSLA?p=TSLA&.tsrc=fin-srch';
const browser = await puppeteer.launch({
headless: false
});
}
Next, you need to call the “newPage()” function to open a new page in the browser, and go to the url that we defined using the “goto()” function:
const puppeteer = require('puppeteer');async function start() {
const url = 'https://finance.yahoo.com/quote/TSLA?p=TSLA&.tsrc=fin-srch';
const browser = await puppeteer.launch({
headless: false
});
const page = await browser.newPage();
await page.goto(url);
}
For this next step, you will have to go to https://finance.yahoo.com/quote/TSLA?p=TSLA&.tsrc=fin-srch, right click on the current stock price and click on inspect:

A pop-up will appear on the right of your window, you will need to find the stock price element:

Next, you will need to right click on the stock price element and click on “copy full Xpath”.
This will give us a way of accessing the stock price element:

Once we have the Xpath of the stock price element, we can add these 3 lines of code into our function:
var element = await page.waitForXPath("put the stock price Xpath here")
var price = await page.evaluate(element => element.textContent, element);
console.log(price);The “page.waitForXPath()” function will locate the stock price element.
Next, the “page.evaluate” function will get the text contents of the stock price element which would then be printed by the “console.log()” function.
At this point, our code should look something like this:
const puppeteer = require('puppeteer');async function start() {
const url = 'https://finance.yahoo.com/quote/TSLA?p=TSLA&.tsrc=fin-srch';
const browser = await puppeteer.launch({
headless: false
});
const page = await browser.newPage();
await page.goto(url);
var element = await page.waitForXPath("/html/body/div[1]/div/div/div[1]/div/div[2]/div/div/div[5]/div/div/div/div[3]/div[1]/div[1]/span[1]")
var price = await page.evaluate(element => element.textContent, element);
console.log(price);
}
start()
If you were to execute your current code, you will find that when going to the url that you defined earlier, a pop-up will appear:
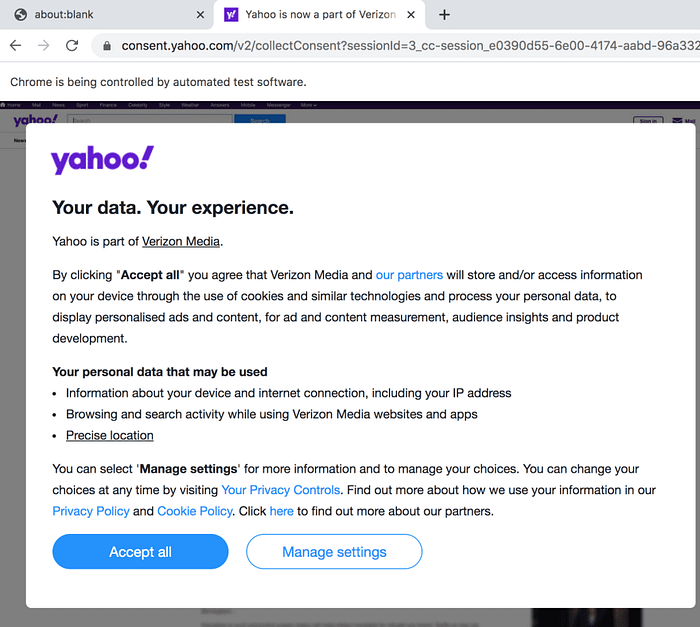
To get around this, plug these 2 lines of code into your function before defining the “element” variable:
var accept = ("#consent-page > div > div > div > form > div.wizard-body > div.actions.couple > button");
await page.click(accept)This will locate the “Accept All” button and click it to make the popup go away.
Now you will have a working function which goes to your defined url, scrapes the latest Tesla stock price and prints it in your terminal.
To go one step further, you can put these lines of code in a for loop:
for(var k = 1; k < 2000; k++){
var element = await page.waitForXPath("/html/body/div[1]/div/div/div[1]/div/div[2]/div/div/div[5]/div/div/div/div[3]/div[1]/div[1]/span[1]")
var price = await page.evaluate(element => element.textContent, element);
console.log(price);
await page.waitForTimeout(1000);
}The “page.waitForTimeout(1000)” function will wait 1000 milliseconds(1 second) before repeating the for loop.
And finally add a “browser.close()” function after the for loop to close the browser and finish your code execution:
const puppeteer = require('puppeteer');async function start() {
const url = 'https://finance.yahoo.com/quote/TSLA?p=TSLA&.tsrc=fin-srch';
const browser = await puppeteer.launch({
headless: false
});
const page = await browser.newPage();
await page.goto(url);
var accept = ("#consent-page > div > div > div > form > div.wizard-body > div.actions.couple > button");
await page.click(accept);
for(var k = 1; k < 2000; k++){
var element = await page.waitForXPath("/html/body/div[1]/div/div/div[1]/div/div[2]/div/div/div[5]/div/div/div/div[3]/div[1]/div[1]/span[1]");
var price = await page.evaluate(element => element.textContent, element);
console.log(price);
await page.waitForTimeout(1000);
}
browser.close();
}
start();
That’s it for this web-scraping tutorial!
If you’re having problems with the code, leave a comment and I’ll see how I can help.
Byeeeeeee 👋
